對運算產業來說,在過去的2016年應該沒有一個概念比人工智慧(AI)更熱門;跨入2017年,專家們表示,人工智慧生態圈的需求成長會更加迅猛。主要集中在為深度神經網路找尋性能和效率更適合的“推理(inference)引擎”。
現在的深度學習系統仰賴軟體定義網路和巨量資料學習產生的超大型運算能力,並靠此來實現目標;遺憾的是,這類型的運算配置是很難嵌入到那些運算能力、記憶體容量大小和頻寬都有限制的系統中(例如汽車、無人機和物聯網設備)。
這為業界帶來了一個新的挑戰──如何透過創新將深度神經網路運算能力嵌入到終端設備中。如(已經被Intel收購的)電腦視覺處理器設計業者Movidius執行長Remi El-Ouazzane在幾個月前就說過,將人工智慧佈署在網路邊緣將會是一個大趨勢。
在問到為什麼人工智慧會被“趕”到網路邊緣的時候,法國原子能委員會(CEA)架構、IC設計與嵌入式軟體(Architecture, IC Design and Embedded Software)部門院士Marc Duranton提出三個原因:安全性(safety)、隱私(privacy)和經濟(economy);他認為這三點是驅動業界在終端處理資料的重要因素,而未來將會衍生更多「儘早將資料轉化為資訊」的需求。
Duranton指出,試想自動駕駛車輛,如果其目標是安全性,那些自動駕駛功能就不應該只仰賴永不中斷的網路連線;還有例如老人在家裡跌倒了,這種情況應該由本地監測裝置在當場就判斷出來,考慮到隱私因素,這是非常重要的。而他補充指出,不必收集家裡10台攝影機的所有影像並傳輸以觸發警報,這也能降低功耗、成本與資料容量。
AI競賽正式展開
從各方面看來,晶片供應商已經意識到推理引擎的成長需求;包括Movidus (Myriad 2), Mobileye (EyeQ 4 & 5) 和Nvidia (Drive PX)在內的眾多半導體公司正競相開發低功耗、高性能的硬體加速器,好讓機器學習功能在嵌入式系統中被更妥善執行。
從這些廠商的動作和SoC的發展方向看來,在後智慧型手機時代,推理引擎已經逐漸成為半導體廠商追逐的下一個目標市場。
在今年稍早,Google推出了張量處理單元(TPU),可說是產業界積極推動機器學習晶片創新的一個轉捩點;Google在發表晶片時表示,TPU每瓦性能較之傳統的FPGA和GPU將會高一個等級,此外並指出這個加速器還被已被應用於今年年初風靡全球的AlphaGo系統。但是迄今Google並未披露TPU的規格細節,也不打算讓該元件在商業市場上銷售。
很多SoC從業者從Google的TPU中得出了一個結論──機器學習需要客製化的架構;但在他們針對機器學習進行晶片設計的時候,他們又會對晶片的架構感到疑惑,同時想知道業界是否已經有了一種評估不同形態下深度神經網路(DNN)性能的工具。
性能評估工具即將問世
CEA表示,該機構已經準備好為推理引擎探索不同的硬體架構,他們已經開發出一種名為N2D2的軟體架構,能夠幫助設計工程師探索和生成DNN架構;Duranton指出:「我們開發這個工具之目的,是為DNN選擇適合的硬體目標。」CEA將會在2017年第一季釋出N2D2的開放源碼。
N2D2的特色在於不僅是以識別精確度為基礎來比較硬體,它還能從處理時間、硬體成本和功耗等多個方面執行比較;Duranton表示,因為針對不同應用的深度學習,需求之硬體設定參數也會有所不同,因此以上幾個比較非常重要。N2D2能為現有CPU、GPU和FPGA等硬體(包括多核心與眾多核心)提供一個性能參考標準。
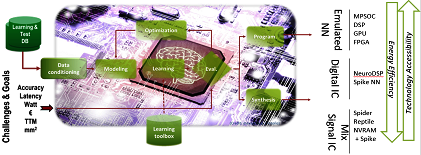
N2D2運作原理
邊緣運算的障礙
CEA已經針對如何把DNN完美地推展到邊緣運算(edge computing)進行了深入研究;Duranton指出,其中最大的障礙在於因為功耗、記憶體容量尺寸和延遲等限制,“浮點”式伺服器方案不適用;而其他障礙還包括:「需要大量的MAC、頻寬和晶片上記憶體容量。」
所以說,採用整數(Integer)而非浮點運算是最需要優先考量的問題…還有別的嗎?Duranton認為,這種專屬架構也需要採用新的編碼方式,例如「棘波編碼(spike coding)」;CEA的研究人員研究了神經網路的特性,發現這種網路能容忍運算誤差,使其適用於「近似運算(approximate computation)」。
如此一來,甚至於不需要採用二進位編碼;而Duranton解釋,其好處在於諸如棘波編碼的時間編碼(temporal coding),能在邊緣運算提供更具能源效益的結果。棘波編碼之所以具吸引力,是因為棘波編碼──或是以事件為基礎(event-based)的──系統能展現實際神經系統內的資料如何被解碼。
此外,以事件為基礎的編碼能相容專用的感測器和預處理(pre-processing)。這種和神經系統極度相似的編碼方式,使得類比和數位混合訊號更容易實現,也能夠幫助研究者打造低功耗的小型硬體加速器。
還有其他能加速將DNN推展到邊緣運算的因素;例如CEA正在考量把神經網路架構本身調整為邊緣運算的潛在可能。Duranton指出,現在人們已經開始討論採用「SqueezeNet」架構而非「AlexNet」架構的神經網路,據了解,前者達到與後者相同精確度所需的參數規格是五十分之一;這類簡單配置對於邊緣運算、拓撲和降低MAC數量都十分關鍵。
而Duranton認為,最終目標是將經典DNN轉換成「嵌入式」網路。
人工智慧(AI)可說是2016年運算領域最熱門的話題,廠商競相開發專用晶片的戰爭已經開打…
CEA的雄心是開發神經形態(neuromorphic)電路;該研究機構認為,這類晶片在深度學習應用中,是從接近感測器的資料(data)提取資訊(information)的有效補充。
在實現以上目標之前,CEA考量了數個權宜之計;例如D2N2這樣的開發工具,對於晶片設計業者開發高水準每瓦TOPS (tera operations per second per Watt)性能的客製化DNN解決方案非常重要。
對於那些想在邊緣運算利用DNN的人來說,也有實際的硬體可以進行試驗──也就是CEA提供的超低功耗可程式加速器P-Neuro;目前的P-Neuro神經網路處理單元是以FPGA為基礎,不過Duranton表示,CEA正要把該FPGA轉為ASIC。
Duranton在CEA的實驗室利用了以FPGA為基礎的P-Neuro展示了搭建了用於臉部是別的卷積神經網路(CNN),並將P-Neuro與嵌入式CPU (在Raspberry Pi上的四核心ARM處理器,以及採用Samsung Exynos處理器的Android平台)進行比較,都執行相同的嵌入式CNN應用,任務是在內含1萬8,000張影像的資料庫進行“人臉特徵提取”。
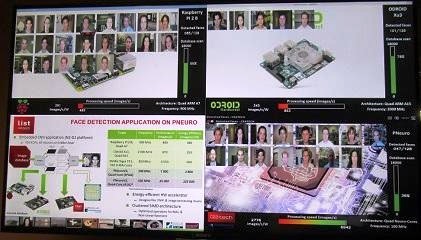
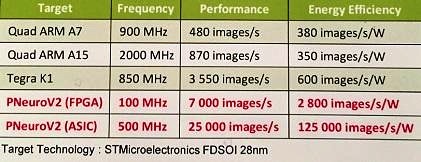
P-Neuro與嵌入式CPU/GPU執行相同人臉識別任務的性能比較
如上表之比較結果,P-Neuro的速度是每秒6,942張圖片,能效則是每瓦2,776張圖片;與嵌入式GPU相較(Tegra K1),運作頻率為1000MHz的P-Neuro速度更快、能效更高。P-Neuro是以叢集式SIMD架構打造,該架構支援最佳化記憶體分層和內部連結。
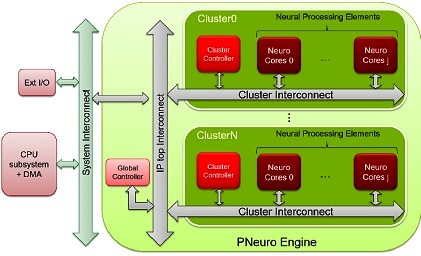
P-Neuro功能區塊
不過對於CEA研究人員來說,P-Neuro只是一個短期方案;目前的P-Neuro是以全CMOS元件打造、採用二進位編碼;該團隊也正在打造採用棘波編碼(spike coding)的全CMOS元件。為充分利用先進製程優勢,並且在密度和功率上有所突破,該團隊設定了更高的目標。
如CEA-Leti的奈米電子技術行銷暨策略總監Carlo Reita在接受採訪時表示,利用先進晶片與記憶體技術來進行專用零組件的實體設計非常重要;其中一個方案是採用CEA-Leti的CoolCube常規monolithic 3D整合技術,另一種方案是採用電阻式記憶體(Resistive RAM)做為突觸(synaptic)元件。此外,如FD-SOI與奈米線等先進技術也將發揮作用。
神經形態處理器
在此同時,歐盟在「EU Horizon 2020」計畫之下,試圖打造神經形態架構晶片,能支援最先進的機器學習,以及基於棘波的學習機制;該研究專案名為NeuRAM3,目標是以超低功耗、可擴展與高度可配置的神經架構,打造在特定應用上功耗較傳統數位方案低50倍的元件。
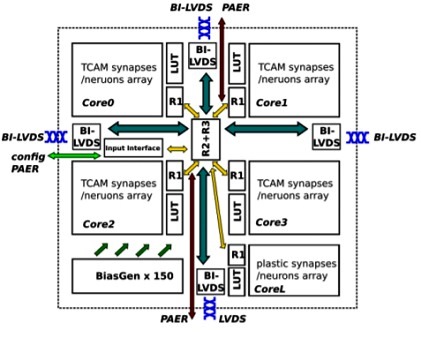
神經形態處理器架構
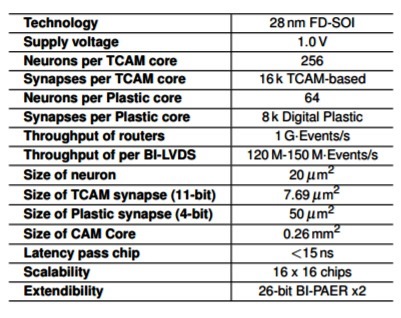
神經形態處理器基本規格
Reita表示,CEA也參與了NeuRAM3專案,該機構的研究目標與該專案的使命緊密相關,包括開發採用FD-SOI製程的單體(monolithically)整合式3D技術,以及整合電阻式記憶體突觸元件的應用;她並指出,NeuRAM3專案開發的新一代混合訊號多核心神經形態元件,與IBM的TrueNorth腦啟發(brain-inspired)運算元件相較,能顯著降低功耗。
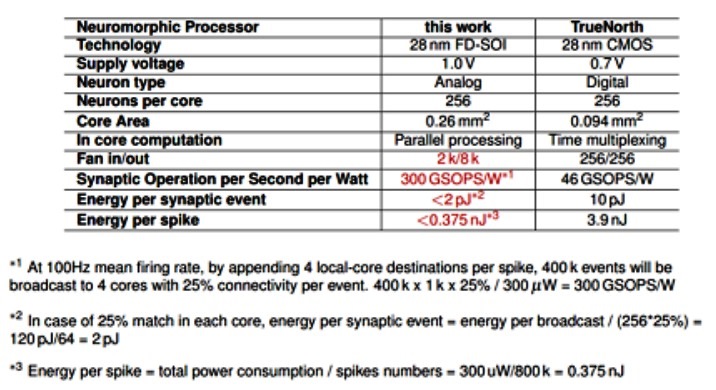
NeuRAM3神經形態元件與IBM TrueNorth的比較
NeuRAM3專案的參與者包括IMEC、IBM Zurich研究中心、意法半導體(ST Microelectronics),義大利研究機構 CNR (The National Research Council in Italy)、西班牙研究機構IMSE (El Instituto de Microelectronica de Sevilla in Spain)、瑞士蘇黎世大學(The University of Zurich)和德國的雅各大學(Jacobs University)。
沒有留言:
張貼留言